Search vs. Recommendations, or Authoritative and Related Sources in a Graph

“They’re making a search engine.”
A bunch of my friends think that. It happens every week or so that I’ll get introduced as “a search engine guy”. And maybe there exists a definition of “search engine” which includes recommendations. But when people think about Google Search vs. Amazon’s recommendations, the difference is between finding and discovering.
Search is about finding. You start with a topic you know exists and you want to find information about it. Recommendations are about discovering things you didn’t know about.

See, there we’ve got a bunch of info about Miles Davis. But that’s the thing — it’s all about Miles Davis. If you already know Miles Davis exists, search is a great way to find out more about him and his music, but it’s awkward for discovering things you don’t know about. Â For comparison:

When looking things related to Miles Davis we get a list of the giants of jazz — most of whom played with Miles Davis at some point in their career. No prior knowledge of Charlie Parker is required in this context. If you know about Miles Davis and want to discover things which are like Miles Davis you need a recommendations engine.
The genesis of graph-based web search was in Jon Kleinberg’s seminal paper Authoritative Sources in a Hyperlinked Environment. Â Kleinberg’s paper predated Brin and Page’s by a few months and was cited in the original PageRank paper. Â From Kleinberg’s abstract:
The central issue we address within our framework is the distillation of broad search topics, through the discovery of “authoritative†information sources on such topics. We propose and test an algorithmic formulation of the notion of authority, based on the relationship between a set of relevant authoritative pages and the set of “hub pages†that join them together in the link structure.
Note the recurring keyword: authoritative.
It turns out that the difference between search and discovery is not just the presentational difference between them — it is also algorithmic. When finding related rather than authoritative source in a graph we massage the data in fairly different ways. In fact, it turns out that authoritative sources are often simply noise in a search for related items. Let’s examine this visually again.

Here we have a mocked up subgraph of Twitter — a few people that are following Barack Obama. When you start a search with Kleinberg’s algorithm (HITS), it begins by extracting a starting set of nodes based on a text search. Let’s imagine here that we’d searched for people mentioning Barack Obama and this was the set of nodes that were returned. Kleinberg’s algorithm attempts to determine the authoritative source in the set, and it’s pretty clear on visual inspection from this set that it’s the node called “Barack Obama”. The algorithm in the paper is naturally a bit more involved — it also incorporates the notion of “hubs”, but we’ll ignore those for now for simplicity. (Incidentally, Kleinberg’s paper is a rare combination of disruptive and accessible and well worth the time to read.)
Now if we were looking through that same subgraph and trying to find related users we’d need to use different logic. That someone is following Barack Obama says very little about them; certainly it doesn’t go far in determining what they’re likely to be interested in. If we were recommending a friend for Matt to follow, visually it’s clear that Jim would be a better recommendation than Bob.
As it turns out, Barack Obama, the “authoritative” node in this graph is in fact just noise when trying to deliver a set of recommendations and it’s best if we ignore it altogether.

Again, as visually confirmed, removing the “authoritative source” from the subgraph makes finding related users for e.g. Matt or Dave much easier.
This problem surfaces all of the time in recommender systems. If we were applying it to finding related artists to Miles Davis, it would be that the terms “jazz” or “music” are far too often linked to Miles Davis and his ilk. On Twitter’s graph it’s people with so many followers that following them says little about a person. In a book store it’s that having bought Harry Potter says little about one’s more specific tastes.
In the early days of Directed Edge, we called this the “tell me something I don’t know” problem. That is, after all, what recommender systems are for. If you recognize all of the results in a set of personalized recommendations, they’re not doing their job of helping you discover things. If something in a set of search results seems unrecognizable, it’s probably just a bad result.
 Follow us on Twitter
Follow us on Twitter Fan us on Facebook
Fan us on Facebook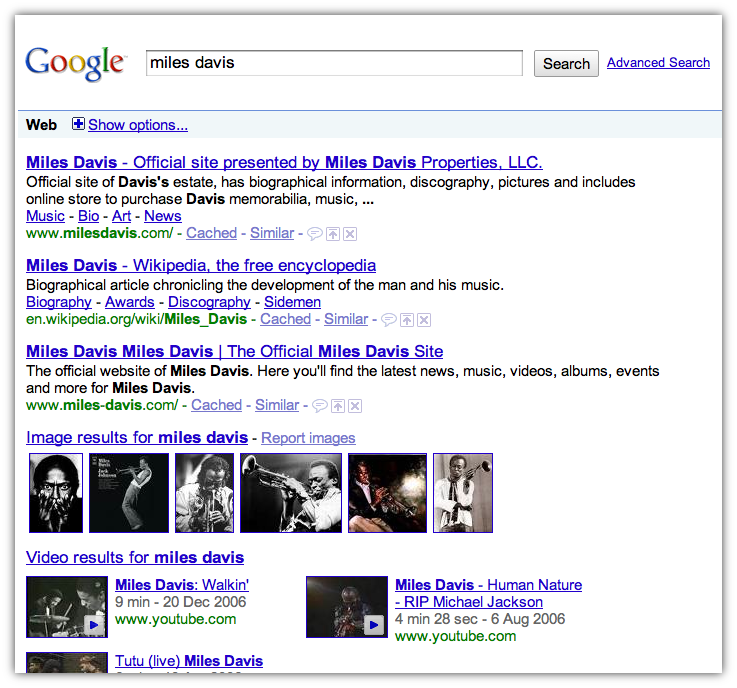{kind=link}
Joseph Turian:
This is a confusion is similar to something we experience with our information exploration and discovery tool.
Search is useful when you know specifically and exactly what you are looking for. But what if you don’t know what information you need?
November 5, 2009, 6:21 pmAditya:
But what if the authoritative sources were more specific. Obama is not a great example because he’s not really an authority on anything specific (politics, maybe, but you wouldn’t follow him on twitter about that).
If the example was @Scobleizer who is an actual authority/connector in the startup world, then he would make for a good authoritative recommendation, right?
So, what I’m saying is that keeping the authoritative source is definitely relevant if your topic is specific enough.
January 31, 2010, 12:10 pm